Lentitud en transferencias TCP: una visión desde la red.
La lentitud en transferencias TCP es uno de los problemas más complicados de resolver por la cantidad de variables involucradas, mientras que otros protocolos como UDP van a alcanzar una mayor tasa de transferencia independientemente de estas variables. Vamos a tener multitud de factores que van a poder impactar negativamente en la transferencia TCP como son la capacidad y disponibilidad de recursos en las máquinas en los extremos, su sistema operativo, la implementación de TCP utilizada, posibles problemas en red, configuraciones específicas dependiendo del ancho de banda y la latencia y elementos intermedios como firewalls. Este contexto generalmente implica la involucración de varios actores (IT, Seguridad, Red corporativa, ISP, fabricantes...), lo que complica aún más el escenario.
El objetivo de esta entrada es analizar algunos de los problemas que pueden estar ocasionados por la red y cómo solucionarlos.
Primero hay que entender cómo funciona TCP a nivel teórico, pero sin entrar excesivamente en detalle porque no es el objetivo. Es un protocolo orientado a conexión con acuse de recibo y que utiliza ventana deslizante como mecanismo de congestión, que va a ser el elemento fundamental a la hora alcanzar la tasa de transferencia esperada o no.
¿Qué es y cómo funciona la ventana deslizante?
Cuando tenemos un protocolo de parada y espera, sucede lo siguiente.

Optimizando el tamaño de ventana
Si analizamos en mayor profundidad, vemos que si aumentamos la latencia y mantenemos el mismo tamaño de ventana (N=3), la comunicación ya no es tan eficiente y vemos que hay mucho tiempo en el que no estamos emitiendo y volvemos a estar desperdiciando ancho de banda.

¿Cómo lo mejoramos? La respuesta parece obvia: aumentando el tamaño de ventana de tal forma que ocupemos el ancho de banda disponible al emitir segmentos constantemente sin tener que esperar hasta el siguiente ACK. En el artículo "Tuning TCP for High Bandwidth-Delay Networks" se explica también el concepto con un unas animaciones muy útiles para entenderlo.

Calculando el tamaño de ventana.
El valor óptimo no es algo que surja aleatoriamente, sino que viene descrito en el RFC 6349 "Framework for TCP Throughput Testing" y se denomina Bandwidth Delay Product cuya fórmula es BDP (bits) = RTT (sec) X BB (bps) donde RTT es la latencia entre las estaciones (Round Trip Time) y BB es el ancho de banda en el cuello de botella de la comunicación, es decir, el ancho de banda disponible para la máquina.
¿Quién determina el tamaño de ventana?
Vale, ya sabemos como calcular el tamaño de ventana, pero ¿qué hacemos con ese valor?¿de qué depende el escoger un valor u otro? Este parámetro lo deciden entre la estación emisora y la estación receptora utilizando la implementación que tengan del protocolo TCP. Aquí intervienen diversos factores y es que, dado que el tamaño de ventana determina el throughput, las implementaciones del protocolo van variando el tamaño de ventana en función de diversos elementos que influyen en el extremo a extremo de la comunicación. El manejo a bajo nivel depende de la implementación concreta de TCP, pero generalmente los parámetros más importantes son:
Por ejemplo, para un enlace de 200M y 182ms de latencia:
BDP (bits) = 182ms X 200M = 4.550.000 bytes*; 4.550.000 bytes/1500 bytes* = 3033 packets
En las siguientes gráficas se puede ver como únicamente cambiando este parámetro los resultados mejoran drásticamente cuando la latencia es alta y con mayor influencia a mayor ancho de banda.

¿Solo un flujo o multiflujo?
Si vemos detenidamente las gráficas anteriores, veremos que en la franja amarilla todavía no habíamos modificado el buffer del router, pero el rendimiento no era tan malo como en la primera prueba. Esto se debe al uso de varios flujos TCP. Hasta ahora, todo lo que habíamos venido analizando corresponde a un solo flujo TCP, es decir, la transferencia de un único fichero entre una estación y otra. Sin embargo, desde el punto de vista de red en la mayor parte de los casos habrá varias estaciones emitiendo y recibiendo flujos TCP en cada sede.
Si tomamos la primera gráfica donde no teníamos la ventana optimizada y añadimos un segundo flujo, vemos que pese a no ser óptima la transferencia es más eficiente en términos de uso de ancho de banda disponible.

Además de esta relación con el BDP, el uso de varios flujos evita lo que se conoce como sincronización TCP, si bien es algo que la mayoría de implementaciones del protocolo evitan actualmente. La cuestión en es la siguiente (más información en este artículo):

El problema de las ráfagas
Como hemos mencionado, el tráfico TCP suele ser bastante rafagoso (bursty en inglés). Esto hace que tengamos que ser cuidadosos a la hora de gestionar estas ráfagas, ya que de lo contrario se producirán pérdidas de paquetes que harán que TCP reduzca el tamaño de ventana y por lo tanto la tasa de transferencia.
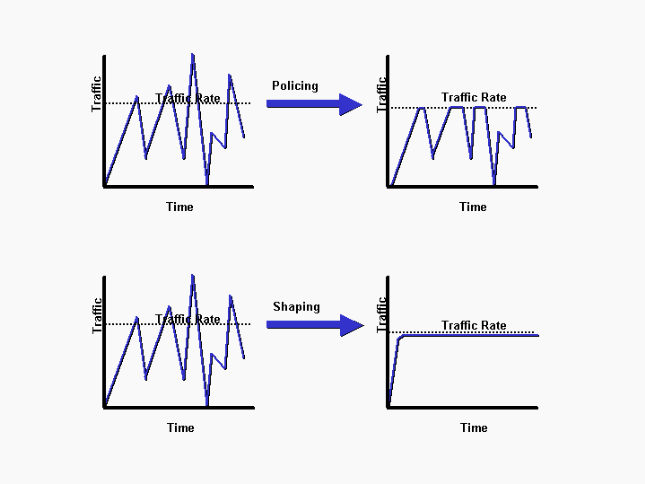
Las ráfagas se gestionan por medio de un 'Shaping', que básicamente lo que hace es utilizar un buffer para dar forma al tráfico de modo que en lugar de descartar paquetes, estos se encolen durante un tiempo hasta que haya espacio. En la imagen inferior de Cisco se ve claramente el efecto que se busca con el Shaping en comparación con un 'policing' puro. Más detalle aquí.
Sin embargo, cuando configuramos el Shaping también permitimos una pequeña ráfaga que en ocasiones puede no corregir el problema que describíamos. Esto se debe a que generalmente esta configuración está en la WAN, donde el proveedor a su vez hará un control del ancho de banda que puede ser menor al que tenemos calculado o no soportar ráfagas. En la imagen inferior se puede observar como la parte en rojo sería descartada por el proveedor, lo que nos llevaría de nuevo a pérdida de paquetes y caída en la tasa de transferencia.

Para solucionarlo, es necesario cumplir los siguientes dos puntos.
El objetivo de esta entrada es analizar algunos de los problemas que pueden estar ocasionados por la red y cómo solucionarlos.
Primero hay que entender cómo funciona TCP a nivel teórico, pero sin entrar excesivamente en detalle porque no es el objetivo. Es un protocolo orientado a conexión con acuse de recibo y que utiliza ventana deslizante como mecanismo de congestión, que va a ser el elemento fundamental a la hora alcanzar la tasa de transferencia esperada o no.
¿Qué es y cómo funciona la ventana deslizante?
Cuando tenemos un protocolo de parada y espera, sucede lo siguiente.
- El emisor envía una trama
- La trama viaja por el medio hasta el receptor
- El receptor recibe la trama, la valida y envía el ACK
- El ACK viaja hasta el emisor
- El emisor envía la siguiente trama y repite el proceso desde 1.
- Se negocia un tamaño de ventana N
- El emisor envía N tramas
- Cada trama viaja por el medio hasta el receptor
- El receptor recibe cada trama, las valida y responde con los ACKs correspondientes
- El emisor envía tramas a medida que recibe los ACK.
Como vemos, la comunicación es más eficiente con ventana deslizante.

Si analizamos en mayor profundidad, vemos que si aumentamos la latencia y mantenemos el mismo tamaño de ventana (N=3), la comunicación ya no es tan eficiente y vemos que hay mucho tiempo en el que no estamos emitiendo y volvemos a estar desperdiciando ancho de banda.


Calculando el tamaño de ventana.
El valor óptimo no es algo que surja aleatoriamente, sino que viene descrito en el RFC 6349 "Framework for TCP Throughput Testing" y se denomina Bandwidth Delay Product cuya fórmula es BDP (bits) = RTT (sec) X BB (bps) donde RTT es la latencia entre las estaciones (Round Trip Time) y BB es el ancho de banda en el cuello de botella de la comunicación, es decir, el ancho de banda disponible para la máquina.
¿Quién determina el tamaño de ventana?
Vale, ya sabemos como calcular el tamaño de ventana, pero ¿qué hacemos con ese valor?¿de qué depende el escoger un valor u otro? Este parámetro lo deciden entre la estación emisora y la estación receptora utilizando la implementación que tengan del protocolo TCP. Aquí intervienen diversos factores y es que, dado que el tamaño de ventana determina el throughput, las implementaciones del protocolo van variando el tamaño de ventana en función de diversos elementos que influyen en el extremo a extremo de la comunicación. El manejo a bajo nivel depende de la implementación concreta de TCP, pero generalmente los parámetros más importantes son:
- La disponibilidad de memoria y procesamiento en las estaciones. Por ejemplo, si el receptor está muy saturado y no puede escribir en memoria todo lo que le llega, pedirá reducir el tamaño de ventana.
- Variaciones en la latencia. Una variación en la latencia puede interpretarse por el protocolo como una saturación del canal de comunicaciones, ya que de alguna forma tiene que saber el protocolo que está alcanzando el BW total del circuito. Sin embargo, estas variaciones también pueden deberse a otros elementos tales como análisis de paquetes por Firewalls o antivirus.
- Pérdida de paquetes. Esta puede deberse debido a descartes en la red por saturación, por ráfagas (el tráfico TCP suele ser rafagoso y generar problemas en este sentido) o incluso por problemas físicos o de negociación, que deberíamos ser capaces de identificar de forma sencilla.
- Factor de escalado de ventana (WS, Window Scale). Es una cuestión de los sistemas operativos en los extremos. Sin entrar en excesivo detalle, en las implementaciones originales el límite del tamaño de ventana es de 65K y para tener valores por encima se introdujo este factor de multiplicación en la RFC 1323. Más info aquí y aquí.
- Otros factores de las máquinas en los extremos a nivel de aplicación y sistema operativo.
Centrándonos en la red
Lo primero de lo que nos tenemos que asegurar es de que tenemos una red 'limpia'. Es decir, no hay pérdida de paquetes, ni problemas de negociación, MTU, etc. Tras ello, también es necesario comprobar que el ancho de banda se alcanza con otros protocolos que no se ven tan influidos por estas variables, como es el caso de UDP.
Lo siguiente es analizar si se produce algún tipo de pérdida de paquetes en el camino y dónde. Esto es muy útil a la hora de centrar el análisis en detalle y para ello es muy útil el uso de contadores que evalúen los paquetes del flujo de tráfico que estemos probando. No vale con un ping para verificar las pérdidas, ya que el nivel de ráfagas de TCP puede provocar pérdidas en algún punto que no sean visibles con otros protocolos.
Volviendo al tamaño de ventana: Dónde utilizamos BDP en la red
Decíamos que el tamaño de ventana determina la tasa de transferencia, pero este tamaño lo definen las estaciones emisora y receptora. No obstante, el BDP es un valor que debemos calcular y utilizar en la red. Concretamente, este el BDP es el tamaño de buffer que debe tener el router, siendo esto particularmente importante en el emisor. Esto es importante particularmente en escenarios con altas latencias, ya que se ven más influidos por el tamaño de ventana como hemos visto anteriormente y los valores por defecto que utiliza Cisco no son óptimos.Por ejemplo, para un enlace de 200M y 182ms de latencia:
BDP (bits) = 182ms X 200M = 4.550.000 bytes*; 4.550.000 bytes/1500 bytes* = 3033 packets
policy-map QoS_Policy
class class-default
queue-limit
3033 packets
policy-map Shaping
class class-default
shape average
200000000
service-policy QoS_Policy
En las siguientes gráficas se puede ver como únicamente cambiando este parámetro los resultados mejoran drásticamente cuando la latencia es alta y con mayor influencia a mayor ancho de banda.

¿Solo un flujo o multiflujo?
Si vemos detenidamente las gráficas anteriores, veremos que en la franja amarilla todavía no habíamos modificado el buffer del router, pero el rendimiento no era tan malo como en la primera prueba. Esto se debe al uso de varios flujos TCP. Hasta ahora, todo lo que habíamos venido analizando corresponde a un solo flujo TCP, es decir, la transferencia de un único fichero entre una estación y otra. Sin embargo, desde el punto de vista de red en la mayor parte de los casos habrá varias estaciones emitiendo y recibiendo flujos TCP en cada sede.
Si tomamos la primera gráfica donde no teníamos la ventana optimizada y añadimos un segundo flujo, vemos que pese a no ser óptima la transferencia es más eficiente en términos de uso de ancho de banda disponible.

Además de esta relación con el BDP, el uso de varios flujos evita lo que se conoce como sincronización TCP, si bien es algo que la mayoría de implementaciones del protocolo evitan actualmente. La cuestión en es la siguiente (más información en este artículo):
- Un solo flujo: Sube la ventana (y throughput) hasta que da el corte. El uso del BW no es óptimo.
- Si hay varios flujos, al utilizarse tail drop, se produce un sincronismo entre los mismos y por lo tanto un uso no efectivo del BW (ver imagen)
- Varios flujos con RED aplicado en las QOS
- Descarta paquetes de flujos TCP aleatoriamente para minimizar la sincronización TCP.
- El descarte se vuelve más agresivo a medida que se llenan las colas.

Como hemos mencionado, el tráfico TCP suele ser bastante rafagoso (bursty en inglés). Esto hace que tengamos que ser cuidadosos a la hora de gestionar estas ráfagas, ya que de lo contrario se producirán pérdidas de paquetes que harán que TCP reduzca el tamaño de ventana y por lo tanto la tasa de transferencia.
Las ráfagas se gestionan por medio de un 'Shaping', que básicamente lo que hace es utilizar un buffer para dar forma al tráfico de modo que en lugar de descartar paquetes, estos se encolen durante un tiempo hasta que haya espacio. En la imagen inferior de Cisco se ve claramente el efecto que se busca con el Shaping en comparación con un 'policing' puro. Más detalle aquí.
Sin embargo, cuando configuramos el Shaping también permitimos una pequeña ráfaga que en ocasiones puede no corregir el problema que describíamos. Esto se debe a que generalmente esta configuración está en la WAN, donde el proveedor a su vez hará un control del ancho de banda que puede ser menor al que tenemos calculado o no soportar ráfagas. En la imagen inferior se puede observar como la parte en rojo sería descartada por el proveedor, lo que nos llevaría de nuevo a pérdida de paquetes y caída en la tasa de transferencia.
Para solucionarlo, es necesario cumplir los siguientes dos puntos.
- Alinear el ancho de banda configurado en el CPE con el del proveedor.
- Minimizar la ráfaga permitida.
policy-map
Shaping
class class-default
service-policy
QoS_Out
shape average
100000000 bps 1 bytes
!
end-policy-map
!
Conclusión
La tasa de transferencia en TCP es una cuestión compleja de analizar sujeta a numerosas variables. Una de las características es que una red a primera vista sin problemas de capacidad o calidad puede no estar optimizada para dar el mayor rendimiento en una transferencia TCP entre dos equipos a una determinada latencia, lo que hace necesario un estudio específico.


Comentarios
Publicar un comentario